Tracking through Containers and Occluders in the Wild
1Columbia University
2Toyota Research Institute
3Woven Planet
Summary
We propose a model, called TCOW (for Tracking through Containers and Occluders in the Wild), that can segment objects in videos with a notion of object permanence, which reflects the fact that objects continue to exist even when they are no longer visible. Our network is trained to predict masks that not only denote the target instance, but also explicitly mark the surrounding occluder or container whenever one exists. We also introduce a new collection of datasets consisting of a photorealistic synthetic training set as well as a real-world evaluation benchmark.
Method
Our framework focuses not only on attempting to localize objects at all times, but also explicitly considers possible containers or occluders that might be in the way. However, supervision for such a task is difficult to obtain. Therefore, we leverage the Kubric simulator to generate scenes with accurate labels for both occlusion and containment events. Next, we train a video transformer model on this dataset to produce segmentation masks to track any target object and temporally propagate a triplet of masks, densely covering the video. Finally, we investigate the model's ability to generalize to a variety of natural videos in the wild.
This direct sim-to-real transfer (without any sophisticated domain adaptation techniques) implies that our network must be able to process complex, out-of-distribution scenes consisting of novel arrangements, complex dynamics, and unfamiliar visual features.
Network Overview
At a high level, given a pointer to the target object in the beginning of the video, our model subsequently generates three masks for every frame in the video clip:
- The target channel mi localizes and segments the instance we are interested in tracking.
- The occluder channel mo reveals which frontmost object is responsible when the target is hidden.
- The container channel mc reveals which outermost object is responsible when the target is enclosed.

Representative Results
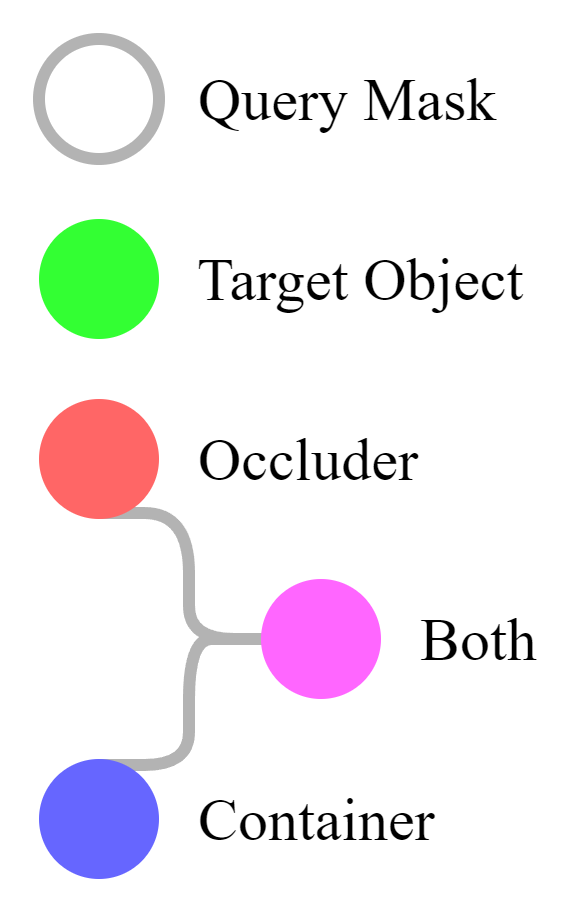
In the videos below, the query mask is briefly visualized by a white outline in the first frame of the video clip. No other masks are given as input to the model for inference. Colored areas indicate dense predictions made by the model over time, and colored borders denote annotated ground truth masks. The legend is shown on the right of every video.
Success Cases
Three dolphins are swimming in an underwater environment, one of which we designate as the target instance that we want to follow over time. This dolphin is initially clearly visible and tracked correctly (in green), but then gets occluded by another dolphin due to relative camera motion. As expected, TCOW predicts an occluder segmentation mask (in red) corresponding to the pixels of the occluding dolphin.
In the next example, TCOW maintains awareness of the identity and position of the duck throughout the depicted long occlusion. Note that the hand briefly acts as the primary occluder of the duck (when the box is pushed a second time), since it resides spatially inbetween the target object and the camera for just a split second.
Amodal Completion
Despite not being the main point of the paper, TCOW displays an ability to both extrapolate and interpolate object boundaries with remarkable precision when they are only partially visible. Note that the tree never becomes marked as an occluder because our chosen formalism requires objects to conceal the target object in nearly its entirety (i.e. at least 95% of its pixels) for that to happen.
Occlusion vs. Containment
Because containment is defined in 3D terms while occlusion is defined in 2D terms, yet both principles can also emerge recursively and in arbitrary compositions, this can sometimes lead to very tricky situations. In the example below, a small package falls into a pot, which is then pushed forward by a larger box. The container is itself first briefly occluded by the larger box, which causes that box to take over the role as primary occluder. Meanwhile, the pot remains the primary container at all times, because the package is still inside of it and gets carried along with the container. Once the box falls down on the ground, it is not occluding the tracked target object anymore, such that the pot ends up becoming both the primary occluder and container of its contents. TCOW recognizes and marks all of these events correctly as they unfold.
Ambiguity
To further demonstrate TCOW's ability to distinguish between containment and occlusion based on subtle visual cues, it is worth performing a controlled study where we let the same mug play multiple roles: initially as a normal container (first clip), but then merely as an occluder without containing anything (second clip).
Now we attempt to trick the model by placing the object behind the mug. A naive model could, hypothetically speaking, learn a shortcut and assign containment based on just the object category that it observes (for example, a mug is typically a container). However, TCOW does not report any containment, yet still detects the occlusion. This finding suggests that TCOW has successfully learned to reason about distinct manifestations of object permanence, and can characterize relationships between objects in an accurate, refined manner.
Cup Shuffling
This highly challenging test set focuses on tracking tiny objects through upside down cups that are repeatedly swapped. The results are sometimes surprisingly decent, as shown in this cherry-picked example. Note that the hand (marked in red) acts as the primary occluder of the cup, hence also of the ball underneath, at the initial placement as well as during the swapping. Once the hand is lifted, the cup itself (marked in magenta) becomes both the primary container and occluder of the ball. TCOW handles these transitions correctly.
Failure Cases
Two similar looking piglets occlude one another, causing TCOW to mistakenly believe that the occluder is the same instance as the first piglet. In general, TCOW tends to be confused more easily by animals and humans since they are considerably out-of-distribution with respect to the Kubric Random training set.
TCOW often struggles with cup shuffling games, especially when the objects or containers involved are physically small, or when there is additional occlusion due to hands. By releasing all data, code, models, and benchmarks (see below), we hope that future research efforts can improve the spatiotemporal reasoning skills of AI systems.
Datasets
We contribute and publish one training set as well as four curated benchmarks for evaluating object permanence as part of our paper. The results shown on this webpage typically include a variety of videos from all datasets, but each specific test set gives rise to different statistics and levels of difficulty as explained in our paper.

|
Kubric Random can be accessed at these links: Train (Part 1), Train (Part 2), Train (Part 3), Train (Part 4), Val, Test. This is our synthetic training set on which the TCOW network was trained. It consists of 3,600 videos, and its total size is 2.45 TB (compressed) or 3.08 TB (extracted). |
|---|---|

|
Kubric Containers can be accessed at this link. It is a scripted synthetic test set with dense annotations. It consists of 27 videos, and its total size is 7.36 GB (compressed) or 9.00 GB (extracted). |

|
Rubric Office can be accessed at this link. It is a real-world test set with sparse annotations of key frames, and is recorded in our lab space. It consists of 32 videos, and its total size is 65.4 MB (compressed) or 65.9 MB (extracted). |

|
Rubric Cup Games can be accessed at this link. It is a real-world test set with sparse annotations of key frames, and is sourced from DeepMind Perception Test. It consists of 14 videos, and its total size is 38.2 MB (compressed) or 38.3 MB (extracted). |

|
Rubric DAV/YTB can be accessed at this link. It is a real-world test set with sparse annotations of key frames, and is sourced from DAVIS-2017 and YouTube-VOS 2019. It consists of 33 videos, and its total size is 425 MB (compressed) or 427 MB (extracted). |
Instructions on how to use them precisely, as well as how to run inference with your own videos, are part of our code release on GitHub.
Paper

Abstract
Tracking objects with persistence in cluttered and dynamic environments remains a difficult challenge for computer vision systems. In this paper, we introduce TCOW, a new benchmark and model for visual tracking through heavy occlusion and containment. We set up a task where the goal is to, given a video sequence, segment both the projected extent of the target object, as well as the surrounding container or occluder whenever one exists. To study this task, we create a mixture of synthetic and annotated real datasets to support both supervised learning and structured evaluation of model performance under various forms of task variation, such as moving or nested containment. We evaluate two recent transformer-based video models and find that while they can be surprisingly capable of tracking targets under certain settings of task variation, there remains a considerable performance gap before we can claim a tracking model to have acquired a true notion of object permanence.BibTeX Citation
@inproceedings{vanhoorick2023tcow,
title={Tracking through Containers and Occluders in the Wild},
author={Van Hoorick, Basile and Tokmakov, Pavel and Stent, Simon and Li, Jie and Vondrick, Carl},
journal={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2023}}
More Results
Video Presentation
Acknowledgements
We thank Revant Teotia, Ruoshi Liu, Scott Geng, and Sruthi Sudhakar for helping record TCOW Rubric videos. This research is based on work partially supported by the Toyota Research Institute, the NSF CAREER Award #2046910, and the NSF Center for Smart Streetscapes (CS3) under NSF Cooperative Agreement No. EEC-2133516. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of the sponsors. The webpage template was inspired by this project page.